

Autoscaling K8s Deployments With External Metrics
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications. It is one of the most widely used container orchestration platforms which enables building systems at internet scale.
Horizontal Pod Autoscaling (HPA) in Kubernetes is one of the container orchestration platform’s major automation capabilities. It simplifies resource management that would otherwise require intensive human effort to achieve.
But, how does HPA work? What kind of metrics can be used to scale a Kubernetes deployment? Is it possible to scale with external metrics? We try to answer these questions below.
Introduction to Kubernetes Deployments & HPA
A Kubernetes Deployment tells Kubernetes how to create or modify instances of the pods that hold a containerized application. Deployments can help to efficiently scale the number of replica pods, enable the rollout of updated code in a controlled manner, or roll back to an earlier deployment version if necessary.
In Kubernetes, HPA automatically updates a workload resource (such as a Deployment), to automatically scale the workload to match demand. But, how does HPA achieve this?
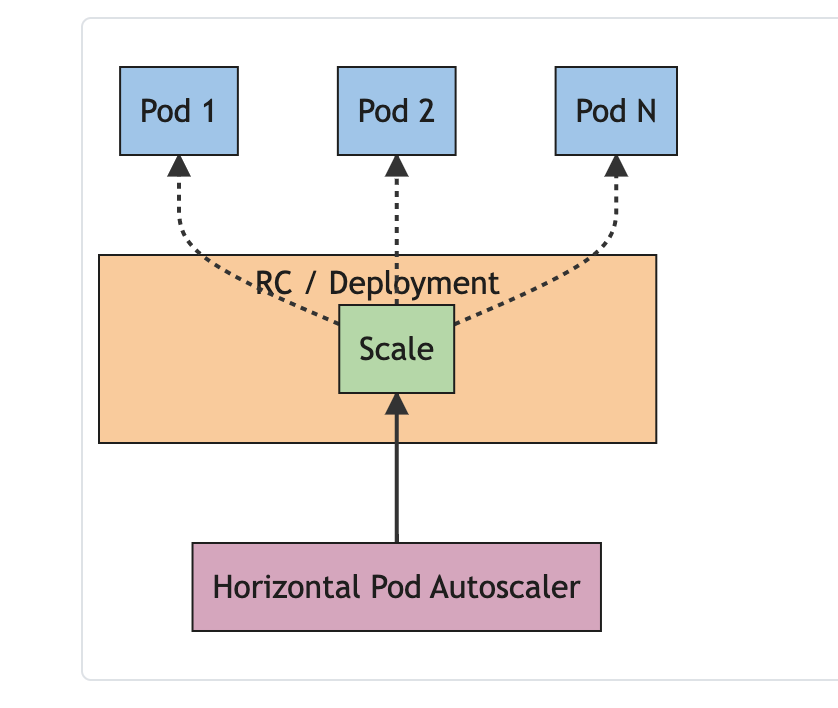
HPAs are implemented as a control loop. This loop requests the metrics API (see Kubernetes Metrics section below) to get stats on current pod metrics every 30 seconds. Then it calculates if the current pod metrics exceed any of its target values. If so, it increases the number of deployment objects.
Kubernetes Metrics
Kubernetes autoscaling is extensible. Using the Kubernetes custom metrics API, you can create auto scalers that use custom metrics that you define.
To autoscale deployments based on custom metrics, we have to provide Kubernetes with the ability to fetch those custom metrics from within the cluster. This is exposed to Kubernetes as an API. By default, the HorizontalPodAutoscaler retrieves metrics from a series of APIs -
- For resource metrics, this is the
metrics.k8s.ioAPI - supports scaling for CPU/Memory based metrics - For custom metrics, this is the
custom.metrics.k8s.ioAPI - supports arbitrary metrics from within the cluster - For external metrics, this is the
external.metrics.k8s.ioAPI - supports metrics coming from outside of the Kubernetes cluster.
How To Autoscale With External Metrics?
Why do we need external metrics? Sometimes, it is not enough to scale a deployment based on internal metrics like CPU usage, memory usage etc. For example, we might want to scale a deployment based on the number of connections on the load balancer or the number of messages in a Kafka topic.
Natively Kubernetes doesn’t collect metrics from outside the cluster, but, Kubernetes is smart because you can extend its metric APIs. The resource metrics, the metrics.k8s.io API, is implemented by the metrics-server. For custom and external metrics, the APIs (custom.metrics.k8s.io or external.metrics.k8s.io) can be implemented by a 3rd party vendor or we can write our own.
Some such implementations are provided by frameworks like Prometheus Adapter or KEDA.
Introduction To KEDA
KEDA (Kubernetes-based Event-driven Autoscaling) is an open-source component developed by Microsoft and Red Hat to allow any Kubernetes workload to benefit from the event-driven architecture model. It is an official CNCF project and is currently a part of the CNCF Sandbox.
KEDA works by horizontally scaling a Kubernetes Deployment. It is built on top of the Kubernetes Horizontal Pod Autoscaler (HPA) and allows the user to leverage External Metrics in Kubernetes to define autoscaling criteria based on information from any event source, such as a Kafka topic lag, length of an Azure Queue, or metrics obtained from a Prometheus query.
How Does KEDA Work?
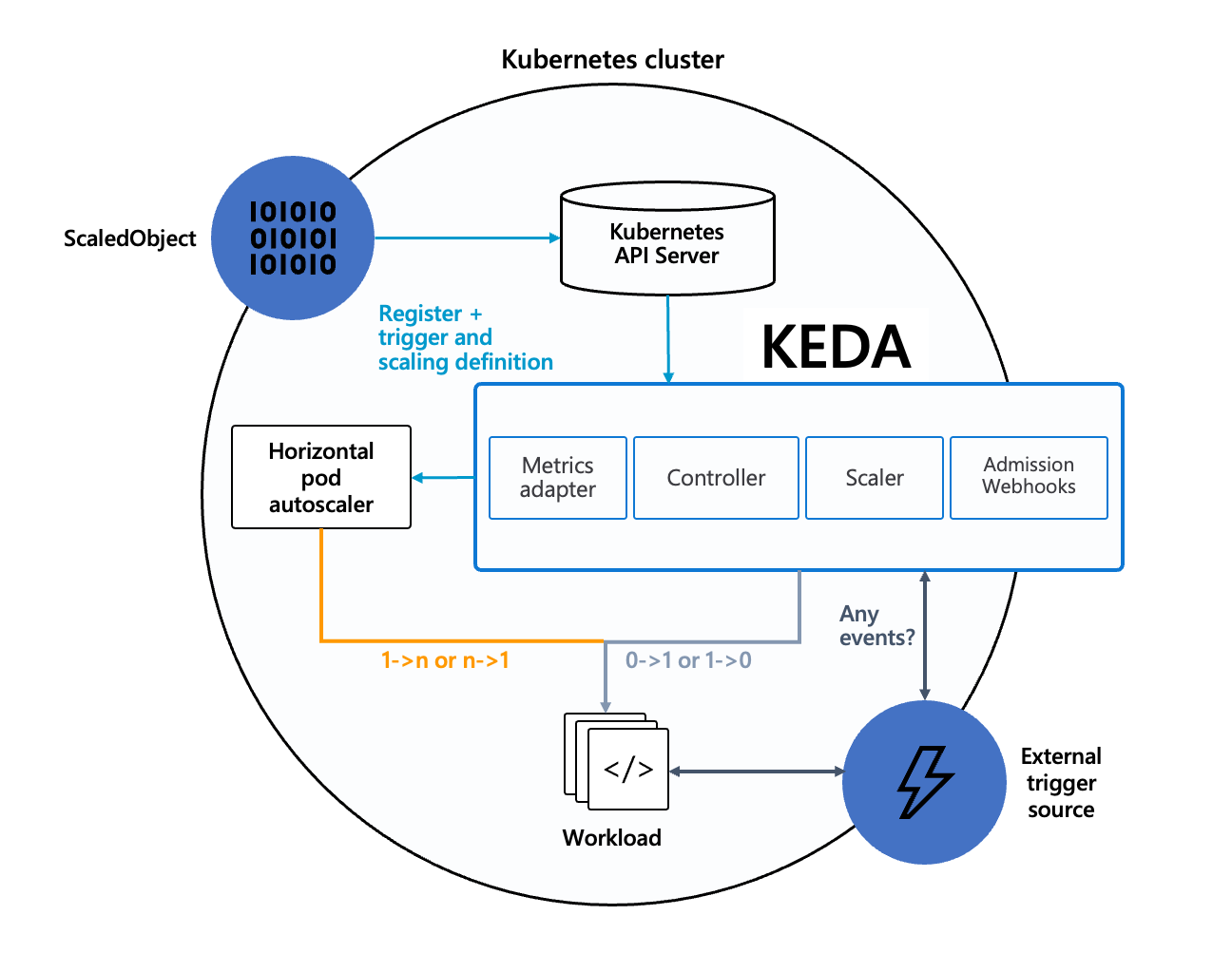
As shown in the above diagram, KEDA provides three basic elements to each cluster:
- Scaler — a component that connects to the selected source (e.g., Kafka) and reads its metrics (e.g., consumer lag)
- Metrics Adapter — an element that forwards the metrics read by Scaler to Horizontal Pod Autoscaler (HPA) to enable horizontal app autoscaling
- Controller — the last, and possibly the most significant, element that provides scaling from 0 to 1 (or from 1 to 0) to the container’s consumer. Why 1 and 0 only? Because the entire solution looks to expand the capabilities of Kubernetes, without delivering any features from scratch. The controller scales to the first instance and further cloning is performed by HPA using the metrics forwarded by Metrics Adapter. The controller is also in charge of continuously monitoring whether a new ScaledObject (described below) deployment appeared.
KEDA Capabilities - Highlights
KEDA provides the following capabilities and features:
- Build sustainable and cost-efficient applications with scale-to-zero capability.
- Scale application workloads to meet demand using a rich catalog of 50+ KEDA scalers
- Autoscale applications with
ScaledObjects, such as Deployments - Use production-grade security by decoupling autoscaling authentication from workloads
- Run CRON-based scalers
- Bring-your-own external scaler to use tailor-made autoscaling decisions
Autoscaling With KEDA
KEDA can be deployed as an independent component within the Kubernetes cluster. More details on installing KEDA can be found here.
When KEDA is installed in the Kubernetes cluster, it creates some custom resources (e.g., scaledobjects.keda.sh, triggerauthentications.keda.sh etc). These custom resources enable us to map an event source (and the authentication to that event source) to a Deployment or Job for scaling.
ScaledObjectsrepresent the desired mapping between an event source (e.g. Kafka) and the Kubernetes DeploymentScaledObjectmay also reference aTriggerAuthenticationorClusterTriggerAuthenticationwhich contains the authentication configuration or secrets to monitor the event source.
ScaledObject Specification
This specification describes the ScaledObject Custom Resource definition which is used to define how KEDA should scale an application and what the triggers are.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
namespace: {namespace}
spec:
scaleTargetRef:
kind: {kind-of-target-resource} # Optional.Default:Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false #Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name}
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}Here scaleTargetRef is the reference to the resource this ScaledObject is configured for. This is the resource KEDA will scale up/down and set up an HPA for, based on the triggers defined in triggers.
To scale Kubernetes Deployments only name is needed to be specified.
-
pollingIntervalis the interval to check each trigger on. By default, KEDA will check each trigger source on every ScaledObject every 30 seconds. cooldownPeriodis the period to wait after the last trigger reported active before scaling the resource back to 0 (or tominReplicaCount). By default, it’s 5 minutes (300 seconds).minReplicaCountis the minimum number of replicas KEDA will scale the resource down to. By default, it scales to zero, but you can use it with some other value as well.maxReplicaCountis passed to the HPA definition that KEDA will create for a given resource and holds the maximum number of replicas of the target resource.
Trigger Specification
This describes the trigger to scale the Deployment up/down. Metrics are collected by KEDA based on the specification here. KEDA supports multiple scalers to trigger scale events. Let's understand this with an example of Kafka as trigger.
triggers:
- type: kafka
metadata:
bootstrapServers: kafka.svc:9092
consumerGroup: my-group
topic: test-topic
lagThreshold: '5'
activationLagThreshold: '3'
allowIdleConsumers: false
excludePersistentLag: false
version: 1.0.0
partitionLimitation: '1,2,10-20,31'
sasl: plaintextbootstrapServers- Comma-separated list of Kafka brokers “hostname:port” to connect to, for bootstrap.consumerGroup- Name of the consumer group used for checking the offset on the topic and processing the related lag.topic- Name of the topic on which processing the offset lag.lagThreshold- Average target value to trigger scaling actions.activationLagThreshold- Target value for activating the scaler.allowIdleConsumers- When set totrue, the number of replicas can exceed the number of partitions on a topic, allowing for idle consumers.excludePersistentLag- When set totrue, the scaler will exclude partition lag for partitions whose current offset is the same as the current offset of the previous polling cycle. This parameter is useful to prevent scaling due to partitions where the current offset message is unable to be consumed.sasl- Kafka SASL auth mode. (Values:plaintext,scram_sha256,scram_sha512,oauthbearerornone, Default:none, Optional). This parameter could also be specified insaslinTriggerAuthentication
Way Ahead At Halodoc
At Halodoc, many of our crucial micro-services are event-driven and hence, the traditional scaling capabilities that are based on Kubernetes and JVM metrics (memory, CPU usage etc.) are not sufficient anymore, as we scale. Hence, we felt the need to evolve the HPA for our deployments to make it capable of acting on external triggers (like Kafka) as well.
- We need to deal with consumer lags effectively
- We need to remove bottlenecks in the system to build on top of Kafka's capabilities
- We need to make sure horizontal scaling kicks in and neutralizes the effects of system inefficiencies so that we meet our SLAs no matter what
- We need to be able to respond to unexpected and unpredictable traffic bursts
It only seems natural that, as the challenges of system scalability, resiliency and robustness evolve, our systems must evolve as well. In our quest to make our systems robust and scale, we are now in the process of actively adopting KEDA as our go-to framework for all our scaling requirements.
Conclusion
As we embark on our way ahead to scalability and robustness of our systems, because of the capabilities discussed above, we found KEDA to be the appropriate partner that can drive our scaling requirements. As far as the results of this adoption go, let's brace ourselves and wait for the next edition of this post!
Join Us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for backend engineers/architects and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke.
We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 1500+ pharmacies in 50 cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application.
We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission.
Our team work tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


