

Reducing Kubernetes(K8s) pod restarts drastically by using an open source tool (pod-restart-info-collector)
In the world of containerised applications, Kubernetes serves as an excellent platform for hosting micro-services. However, when it comes to identifying recurring pod restarts caused by either application issues or problems in the underlying infrastructure, it becomes a challenging task. Moreover, identifying the reasons behind these restarts using Kubernetes built-in commands requires manual effort and time.
The occurrence of pod restarts can result in increased load on other pods, causing temporary service unavailability and potential negative impact on the user experience. To ensure the stability and availability of our applications, it became crucial for us to identify and address the root causes behind these pod restarts.
To automate the task of identifying root cause behind frequent pod restarts, we realised the importance of capturing all events that transpire during a restart. This prompted us to employ the pod-restart-info-collector, a tool which allowed us to gather detailed information including timestamps, error codes, logs, pod and node events. This effective approach enhanced our troubleshooting process, allowing us to isolate issues, and take effective measures to resolve them.
Choosing the right tool for effective troubleshooting
At Halodoc, we use New Relic as our monitoring tool, which offers valuable insights into our application's performance. However, in order to further improve our troubleshooting of pod restarts, we require more extensive insights like node events, pod events and application logs during pod restart.
Our search for a more comprehensive solution led us to discover an open source tool called as pod-restart-info-collector. This simple tool provides all the necessary information like node status, pod status, node events, pod events and application logs for effective troubleshooting. Additionally, the pod-restart-info-collector offered integration with Slack, allowing us to set up alerts and receive notifications in real-time. This effective alerting mechanism helped our team to promptly address pod restarts and reduce end user impacts.
What is pod-restart-info-collector?
The pod-restart-info-collector is an open-source tool for troubleshooting pod restarts in Kubernetes clusters. This tool not only captures detailed information during pod restarts but also sends slack alerts with essential details. These alerts helped us with comprehensive insights, including the timestamp, namespace, pod name, status, events and logs during the pod restart.
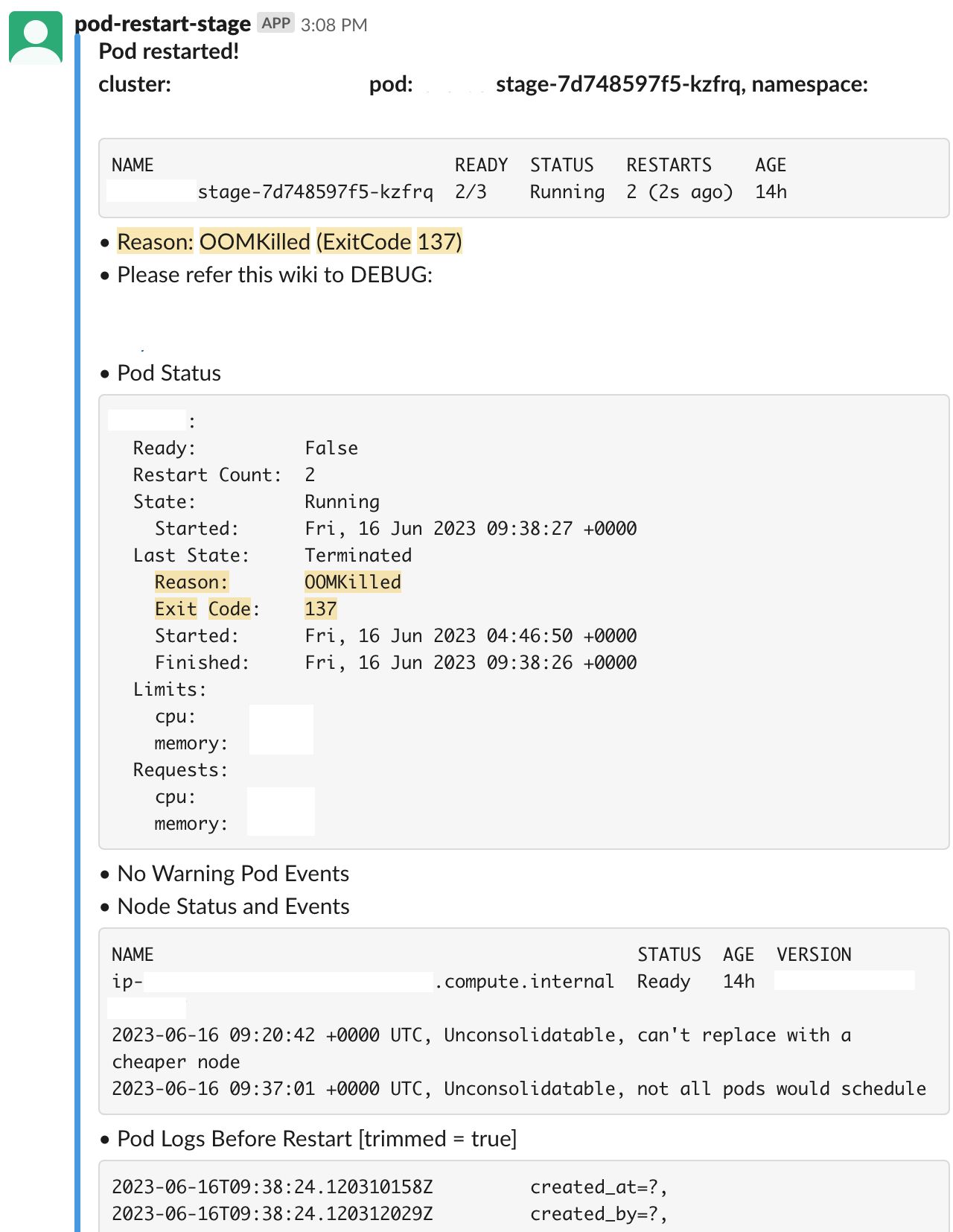
Take a look at the image above showcasing an example of a Slack alert generated by the pod-restart-info-collector. This handy tool provides valuable information in a user-friendly format. In the alert, the Pod Status section gives insights into important details such as Restart Count, Current State, Last State, Reason, Container Limits, and Requests.
The Pod Events section shows the readiness and liveness probe status, while the Node Events section displays the current node status. Additionally, the Pod Logs Before Restart section presents the logs captured right before the restart.
Enhancements to pod-restart-info-collector
The enhancements and configurations described in this section are customised according to Halodoc's specific requirements. Readers are advised to extend or modify these settings based on their needs.
- Enhanced troubleshooting guide: Developed a detailed wiki containing step-by-step instructions to debug pod restarts based on error code and restart reason. This wiki not only explains the possible causes behind specific error codes and reasons but also offers the necessary steps to resolve them. Additionally, it includes point of contact to address these restarts. Furthermore, we have seamlessly integrated this wiki with our alerting system, ensuring effortless access to the troubleshooting guide.
- Bug fix and open-source contribution: Addressed a bug that previously caused inaccurate retrieval of container resource requests and limits when multiple containers were present in a pod. This fix has been shared with the open-source community.
- Improved log retrieval: Introduced a new environment variable, logTail lines, to specify the desired number of lines to fetch from the pod logs before a restart. Additionally, if the log size exceeds slack's limitations, the complete log file is now attached as a reply to the same alert.
- Resource utilisation reporting: Incorporated a resource utilisation section into the alert, providing insights into the resource usage at the time of the pod restart.
Above enhancements to the pod-restart-info-collector have greatly helped to identify and resolve pod restart issues. For instance, by referencing the pod debug wiki, we can quickly identify specific issues based on exit codes. Exit code 1 indicates application runtime errors, exit code 139 suggests OutOfMemoryErrors and exit code 137 points to CPU exhaustion.
Uncovering and Resolving Pod Restarts
Example 1: JVM OutOfMemoryError - Heap Space
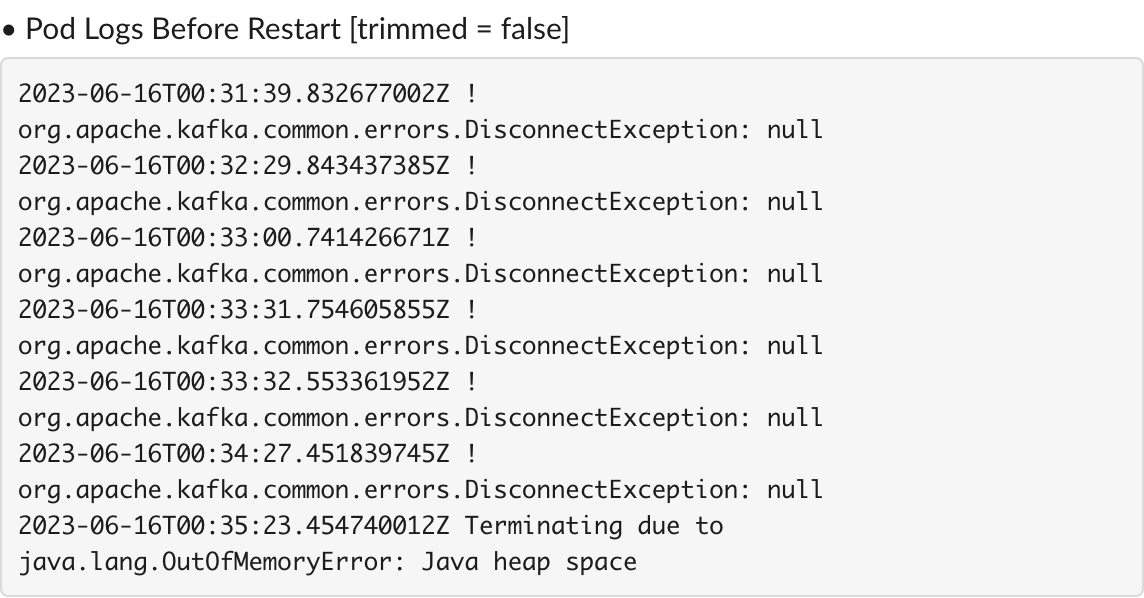
As you can see in the above image, the alert logs show that the pod restarted due to a JVM out-of-memory error caused by heap space exhaustion. By analysing the pod logs from the alert, we were able to identify the specific error and its underlying cause. After careful analysis and experimentation, we decided that there should be at least 550 MB of buffer between the used heap and the maximum heap and 750 MB of buffer between the maximum heap and the total pod memory. Implementing these changes across our pod deployments resulted in a remarkable 70% reduction in pod restarts related to OutOfMemoryErrors.
Example 2: Runtime exceptions from application
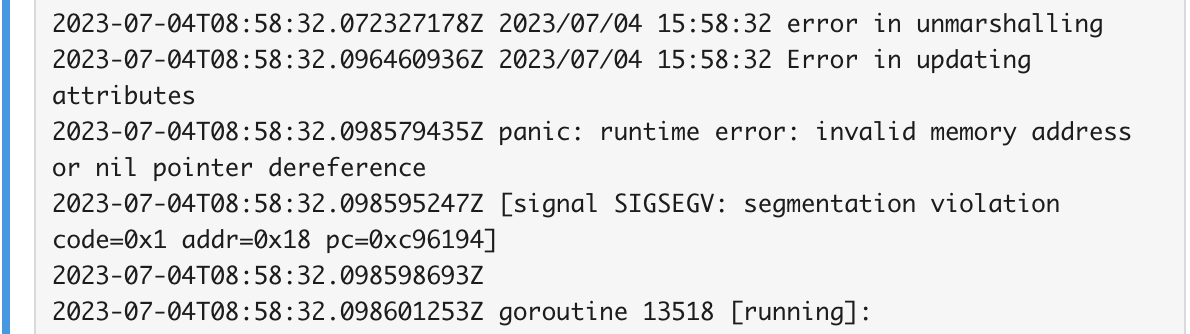
In the above alert image, we can see a pod restart triggered by a Go runtime nil pointer exception. By analysing the stack trace and logs from the alert, we identified the specific runtime error within our application code.
These insights allowed us to pinpoint the problematic area in our code and implement the necessary fixes. By addressing the runtime exception, we not only resolved the pod restart but also enhanced the overall stability and resilience of our systems.
Future Enhancements
As part of our ongoing efforts to enhance our alerting system, we have planned to have a new feature that will tag the respective SRE (Site Reliability Engineering) pod member who is directly responsible for that service for every pod restart slack alert. This enhancement aims to streamline communication and collaboration between SRE and developers, ensuring quick and effective resolution for pod restarts.
Conclusion
In conclusion, The pod-restart-info-collector is an effective tool for troubleshooting pod restarts in our Kubernetes environment. With its detailed insights from multiple source of events, we successfully resolved more than 98.5% of pod restarts, leading to improved system stability. Our enhancements, such as the troubleshooting wiki, resource utilisation section have further enhanced the tool's capabilities. By contributing to the open-source community, we aim to promote knowledge sharing and continuous improvement. Overall, the pod-restart-info-collector has been instrumental in streamlining pod restart troubleshooting. We highly recommend its adoption for effective pod restart resolution.
References
- https://github.com/airwallex/k8s-pod-restart-info-collector
- https://medium.com/airwallex-engineering/automated-troubleshooting-of-kubernetes-pods-issues-c6463bed2f29
Join us
At Halodoc tech, we prioritise scalability, reliability, and maintainability in everything we build. If you thrive on solving challenging problems with rigorous requirements, we invite you to join our team. Whether you are an experienced engineer or just starting your career, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is Indonesia's leading healthcare application. Our mission is to simplify and deliver quality healthcare services across Indonesia, from Sabang to Merauke. Through our Tele-consultation service, we connect over 20,000 doctors with patients in need. We have partnered with 4000+ pharmacies in 100+ cities to provide medicine delivery to your doorstep. Additionally, our collaboration with Indonesia's largest lab provider allows us to offer lab home services. To enhance our services, we recently launched a premium appointment service in partnership with over 500 hospitals, enabling patients to book doctor appointments within our application. We are grateful for the trust and support of our investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With a recent Series C funding round and a total raised amount of approximately USD$180 million, we are dedicated to simplifying healthcare for Indonesia. Our passionate team is committed to creating a personalized healthcare solution that meets all our patients' needs. Join us as we strive to revolutionize healthcare accessibility and delivery in Indonesia.


