

Utilizing the Power of Machine Learning in Hospital Invoice Details Extraction
In this blog we explain the importance of automation for the itemized billing process for hospital invoices, and how we build column identifier model where it identify column name based on column values. At development stage of this project, we collaborated with Insurance team where there were discussions about problems, providing data, feedbacks about model predictions, and etc.
Background
Halodoc app has a feature where we can connect our insurance policy to Halodoc account, utilise services and have the insurance company pay for the eligible services. We work with multiple insurance providers.
It's a common thing where we need to submit insurance claim to insurance company. And Halodoc work as Third-Party Administrator (TPA) where we provides operational services such as claims processing and employee benefits management under contract to Insurance companies.
Insurance claim is a formal request by a policyholder to an insurance company for coverage or compensation for a covered loss or policy event. The insurance company validates the claim (or denies the claim).
If it is approved, the insurance company will issue payment to the insured or an approved interested party on behalf of the insured
There are 2 types of insurance claims:
- Cashless
- Reimbursement
For reimbursement type, when we submit an insurance claim we need to provide several documents such as claim form, diagnosis report, ID proof, prescription, invoices.
Problem
Business problem
For reimbursement mechanism, we receive thousands of claim documents per day in PDF format, each PDF document containing multiple images. And our claim team need to perform itemized billing for each of the claim document.
Itemized billing is a manual process where Claim team needs to document each item charged to a patient (R&B, all individual medicines and services).
This process was fully manual and time consuming. This meant that the time taken to approve an insurance claim took long time, resulting in a slow process of copy and pasting items. The slow process is due to the fact that we have to document each item in a claim that can have more than 50 items (referring to most Inpatient claims). It takes our claim admin ~60 minutes to journal the data from this claim.
In order to approve claims quickly, we wanted to solve the itemized billing problem using machine learning.
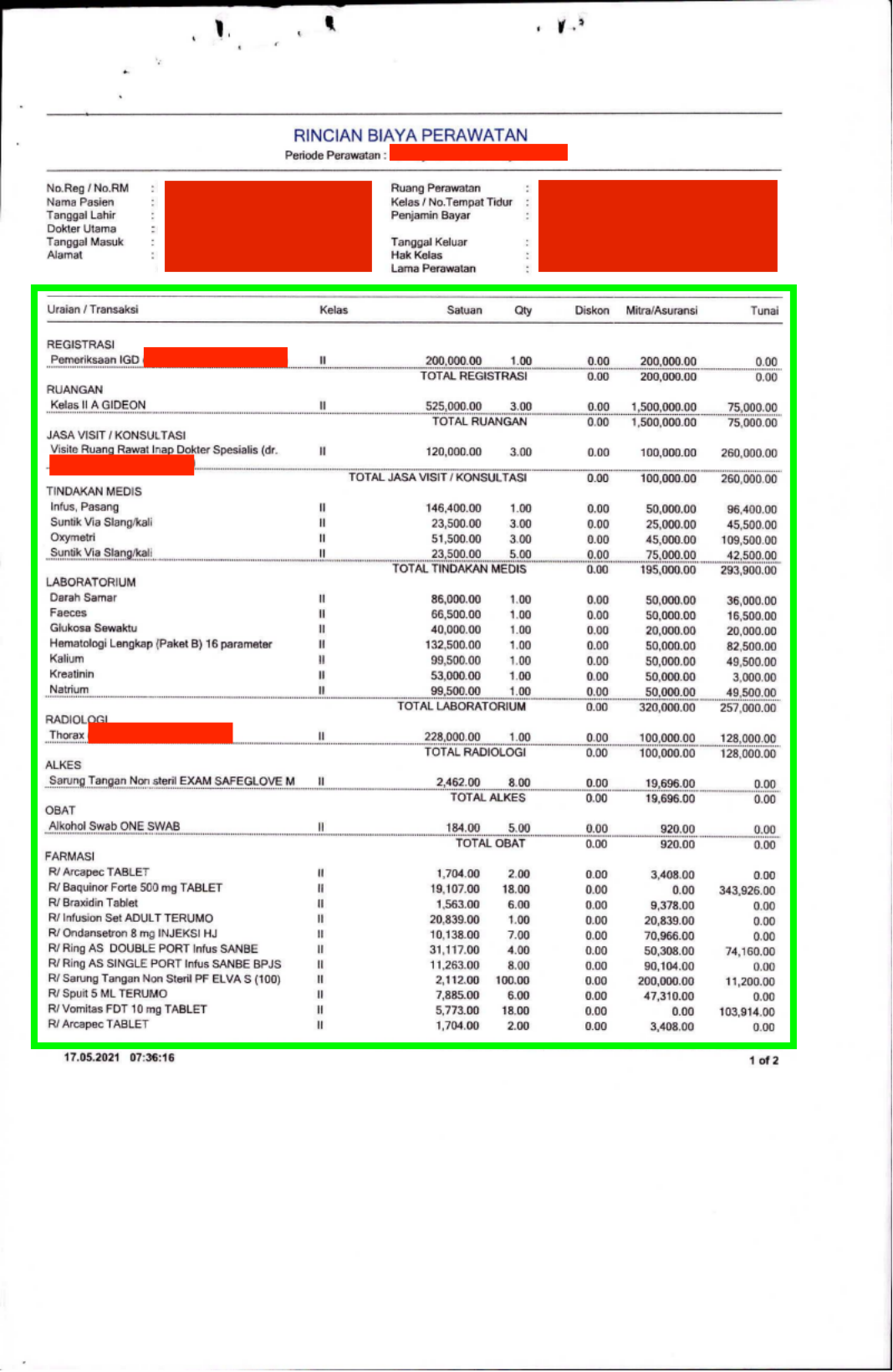
Technical Problem
Itemized Billing process:
- Table detection (showed by Green rectangle on invoice image)
- Table structure recognition where it detects table cell (row location, column location)
- Text recognition for all table cell --> output will be in dataframe format
- Column identifier where it identify column name based on column values
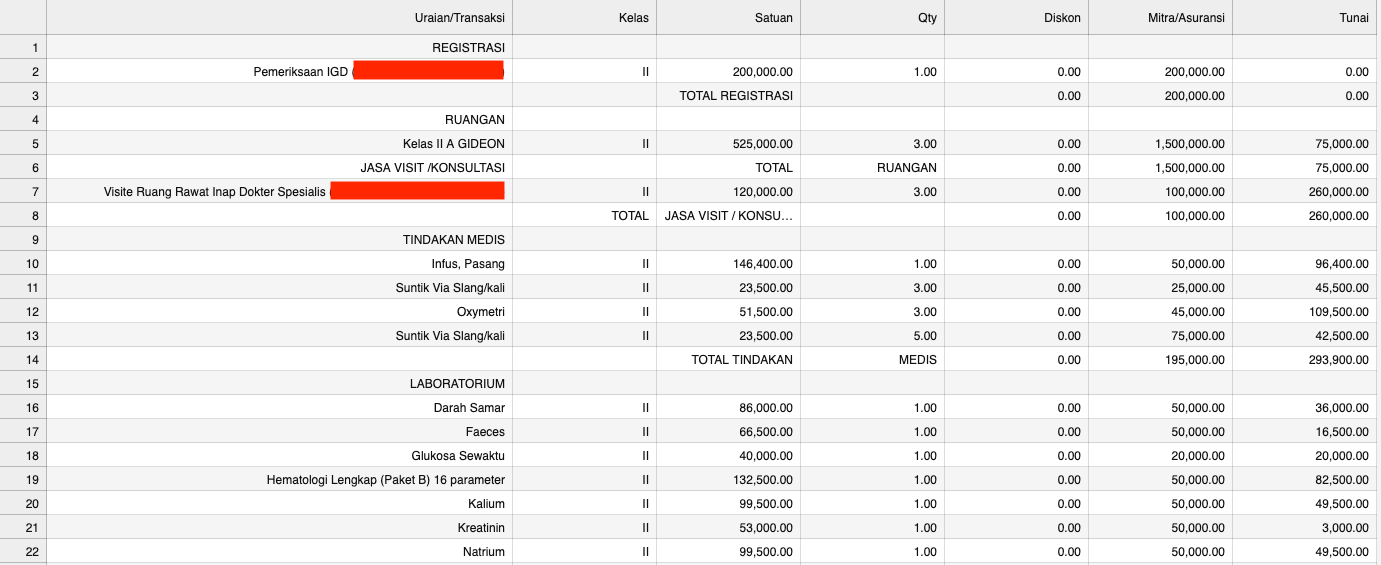
For the rest of this article, we will focus to discuss about step number 4
Column Identifier
Why we need to identify column name?
- We wanted to get specific information about date, item name, quantity, and price
- Invoice table do not always have header/column name
- Every hospital has their own invoice format, it's mean that there are a lot of name variations for table column
Even when we have column name information is can be tricky to validate it using string matching approaches such as Fuzzy Matching. That's why we ended up building a machine learning model to predict these column name based on column values, where this approach more robust to tackle the problem
Dataset
Basically, we created synthetic dataset based on sample of hospital invoice and internal data that we had. Our dataset generator will create column values (text) along with their labels (date, item, quantity, price, unknown).
In real life, we found that column values sometimes contains empty string (““) and noise word because of result from either table structure recognition or text recognition. Based on that, we add some noise pattern in our generator rule such as empty string (""), noise word ("abcde"), noise zero ("0"), and noise stopword ("subtotal", "charge"). When we create synthetic dataset we want it to represent real dataset where it have same characteristic and pattern.
Feature Engineering
In this step, we process and transform text data into feature which are vectors representation.
These are the following steps:
- Combine column values which are list of data into single sentence
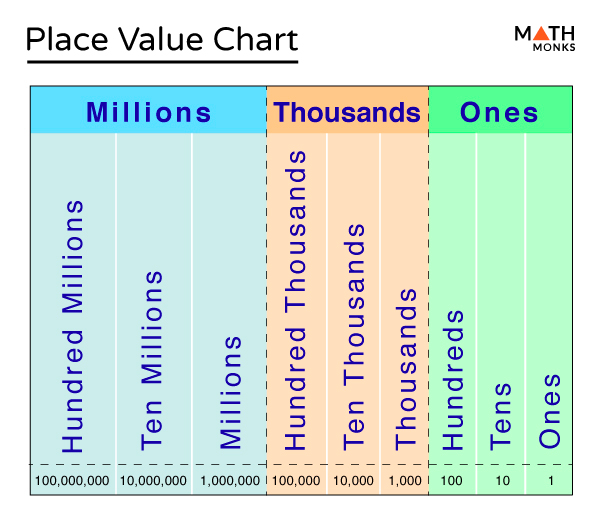
- Convert number to text representation based on number placement chart
e.g. (155 → “hundreds“, 2.354 → “thousands“, 3.000.000,00 → “millions“) - Convert text to embedding IDs using bpemb
- bpemb is pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE)
- We use embedding that trained on Indonesia Wikipedia with 100K vocabulary size and 50 embedding dimension - Handle maximum length of sequence using padding & truncating (
max_len = 40)
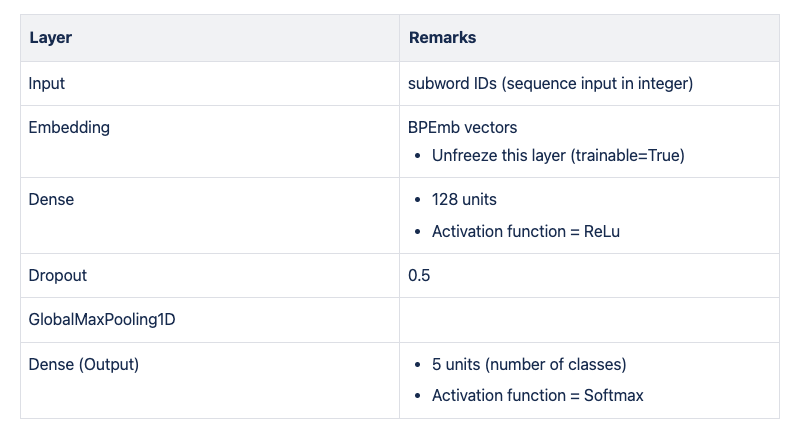
Model Architecture
- Data Science problem: classification with number of classes = 5 (
date, item, quantity, price, unknown). - Model: Multi Layer Perceptron (MLP)
- Loss function: Categorical Crossentropy
- Optimizer: Adam
- Metrics: Precision and Recall
- Batch size: 256
- Epochs: 30
Conclusion
This blog basically explained the importance of automation for the itemized billing process for hospital invoices, and how we built column identifier model where we identified column name based on column values. At development stage of this project, we collaborated with Insurance team where there were discussions about problems, providing data, feedbacks about model predictions, and etc.
This project bring some values to Halodoc such as:
- Reduced time in claims processing
- Cost savings in terms of manpower
- Reduced potential human errors, which can lead to the inclusion of invalid data.
References
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and in total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


