

Data Quality Pipeline using Great Expectations @ Halodoc
Data Quality is a key factor in data analytics, as it helps to ensure that data used in analytics is reliable and accurate. Poor data quality can lead to inaccurate analysis and incorrect conclusions. To ensure data quality, it is important to have a system in place that detects errors, identify discrepancies, and correct errors. It also involves monitoring data over time to ensure that it continues to meet quality standards.
At Halodoc, we are trying to implement data quality over the data life cycle to create both qualitative and quantitative data available. In this blog you'll see how we used a tool called Great Expectations to build a Data Reconcilation framework which does the data quality checks while it is transformed from raw to processed zone.
What is Data quality ?
Data quality is the measure of how accurate, reliable, and relevant the data is for its intended purpose. It is important for businesses and organisations as it ensures that data is of high quality and that it can be used to make decisions with confidence. Data quality can be monitored through a variety of methods, such as data profiling, data cleansing, and data validation. By having high-quality data, businesses can have more confidence in their decisions and improve their overall operations.
What we are solving :
- Accuracy
- Timeliness
- Completeness
- Uniqueness
- Validity
- Consistency
Need for Data Quality at Halodoc
Since the rise of more data sources and complex data pipelines, it becomes necessity for data teams to leverage data quality over different transformations.
We have divided the framework into three phases : Data Reconcilation, Validation and quality.
We have implemented the data quality pipeline which is decoupled from ETL pipelines to execute quality checks in our raw to process data transformation.
Using Great Expectations for Data Quality Assessment
Great Expectations is an open source tool which provides a mechanism for “assert what you expect” from your data in the form of unit tests.It allows to be run on a range of different data volumes from small batches of data to more complex transformations. Since it had better connectivity with different database sources and data manipulation frameworks like Pandas and Spark for big data, it was a great fit for the development of our data platform, as it can be integrated with Airflow. In our earlier blogs, you can see the components which are used for our data platform.With Great expectations we have used built in expectations and created our own custom expectations for our common use cases.
Architecture
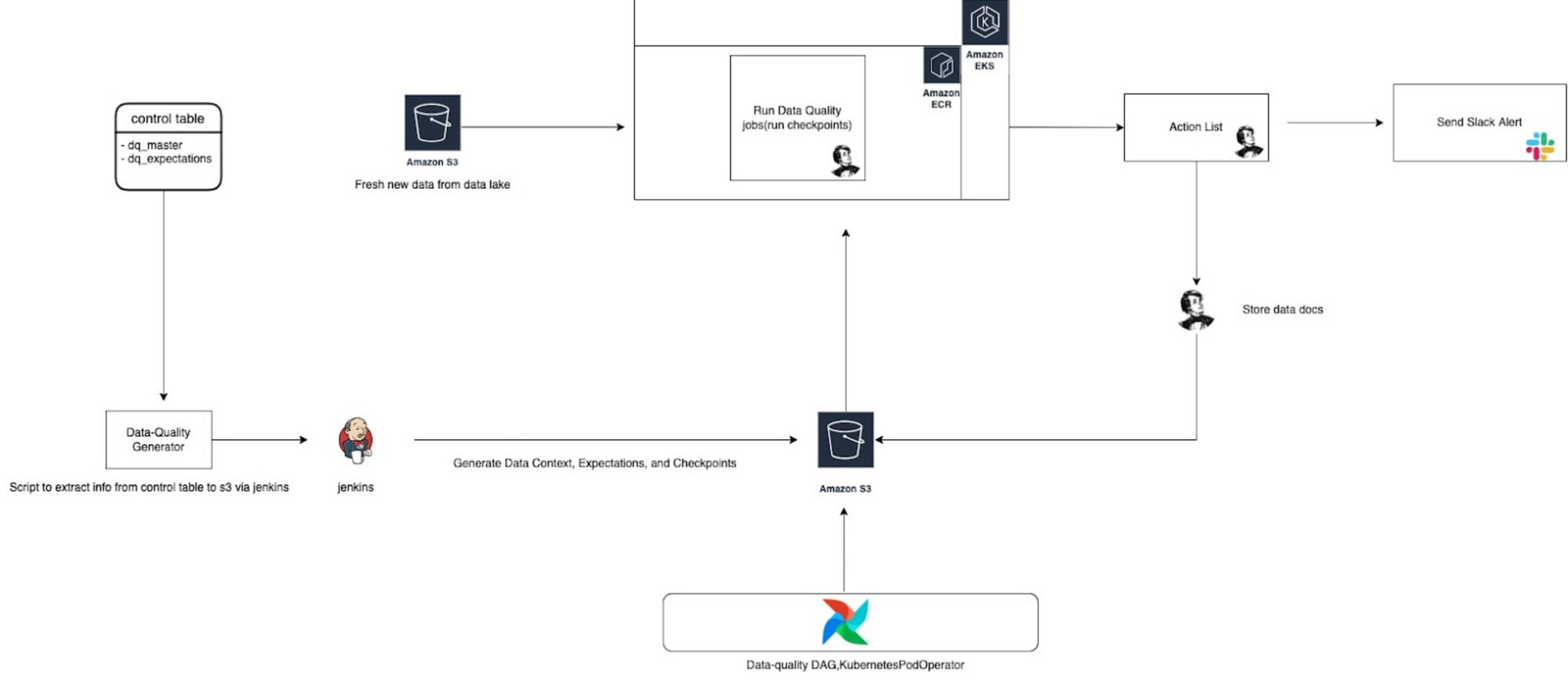
Key Components
Control Table - DQ Tables
Same principle like other services that are built in the lakehouse at halodoc, we also utilise control tables as our metadata for data quality. The idea is to have abstraction level information in the control table, and generate the actual data into S3. In our control table we have 2 tables for data quality:
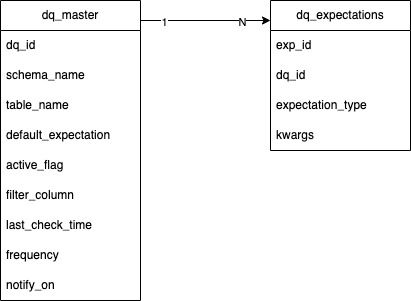
- dq_master, hold metadata information about the datasource which in our use cases is tables that we have in datalake.
- dq_expectations, hold metadata about the expectations that need to be attached to dq_master using the dq_id as join key.
The relationship between dq_master and dq_expectations is one to many, which can be translated into, one table (datasource) can have more then one expectation.
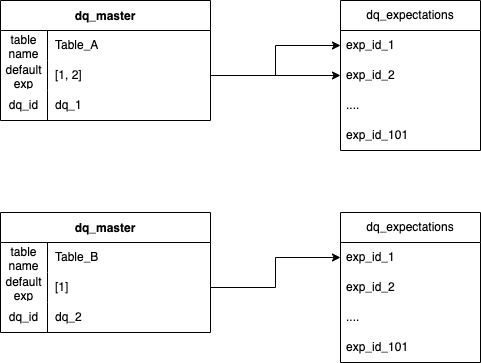
default_expectations - this column brings the abstraction relation between dq_master and dq_expectations, the idea is to make one general expectation to be used by many dq_master (datasources).
Generator
In order for dq_master & dq_expectations to be used by the GE framework, it needs to be extracted from the control table to S3. To do so we create a Python script to extract the data that we have in the control table, and put it into the s3 store.
S3 Store
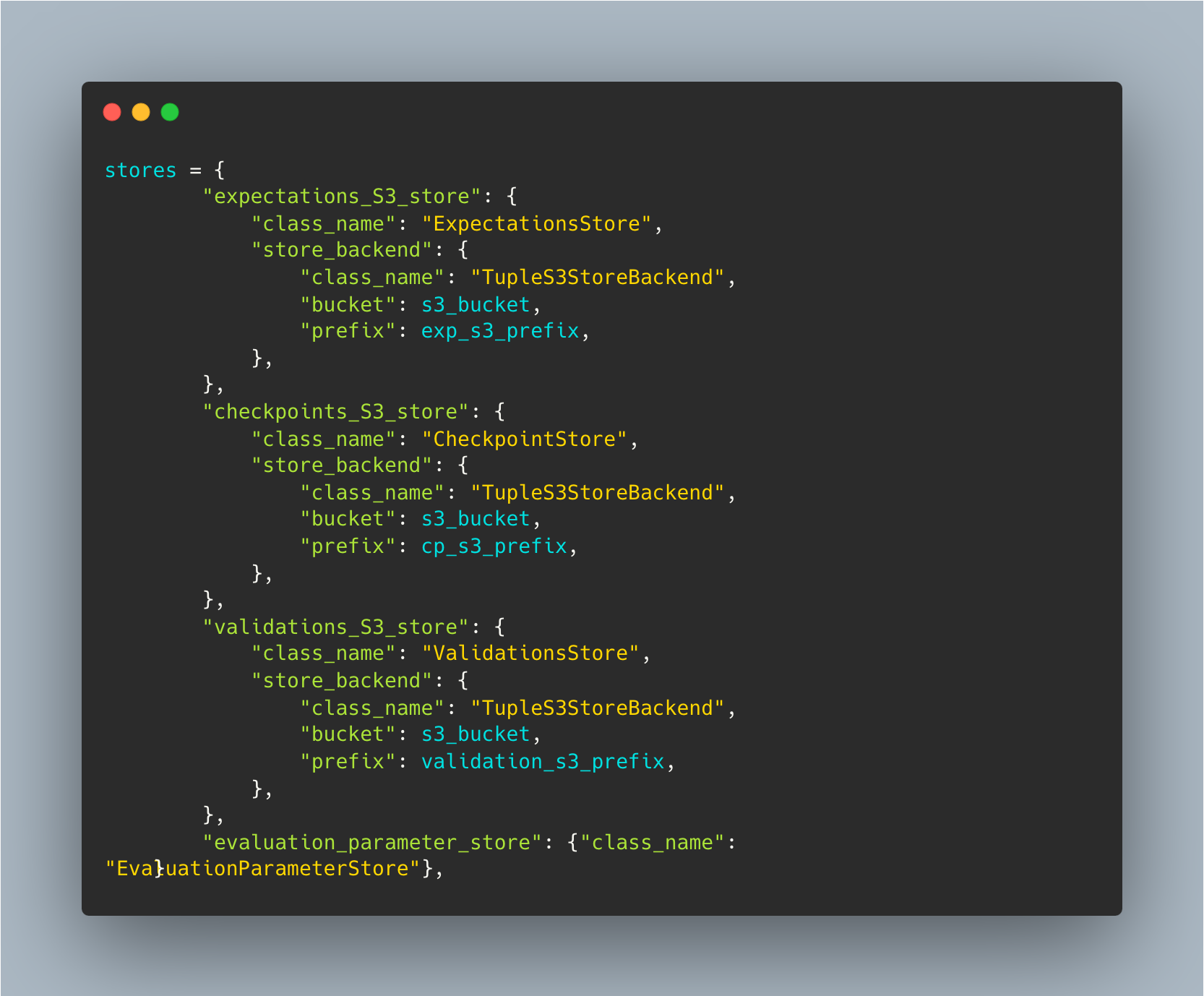
Once the data from the control table is extracted to S3, the data can be directly used by the GE framework. The information that store in S3 store:
- Expectations - These are the expectations generated from the GE framework , which includes the json file of type of expectations to be used on the table/dataset which are called as Expectation suites similar to Test suites in Software Testing. For e.g. : expect_column_values_to_be_unique, expect_column_max_to_be_between.
- Checkpoints - Checkpoints are used to store the results of running expectations against a dataset that are stored in s3. This allows our team to track the quality of their data over time and quickly identify any issues that may arise.
- Validations - Validations are the process of running a set of expectations against a dataset and comparing the results to the stored checkpoint.This helps us to quickly identify any differences between the current state of the data and the expected state.
By default data_context GE will look up that information in the local subdirectory under great_expectations/, to change this in the great_expectations.yaml or in the data_context parameter we need to specify the S3 store locations.
Datasources
As for data sources we already specified in dq_master in control table which table in datalake that will become the datasource. In the process we use AWS Wrangler connected to Athena to get the data from the tables, and load it into python-pandas dataframe. Once it is loaded it will become our batch_request parameter that feeds into run_checkpoint.
Orchestration
As for orchestration we use Airflow, to run the checkpoints in the schedule base and also send the alert of data validation on slack.
Container
For running the checkpoints, we use the Kubernetes pod (AWS EKS) as our compute engine. We have already put our checkpoint script in a prebuilt container and registered it in AWS ECR. When the Airflow schedule job is triggered, it will run the KubernetesPodOperator, which will run the checkpoint script in the Kubernetes pod.
Slack Alert :
After the code run is completed, it sends the Slack alert containing metadata about
- Expectation suite name
- Data asset name
- Run and Batch ID
- Summary whether the expectation is met or not.
- Link to Data Docs.
Slack alert helps in monitoring of data health check, if the expectation is not met the data engineering team can request for data fix at either source or they troubleshoot the data anomaly in the pipeline.
Schedule Job Workflow
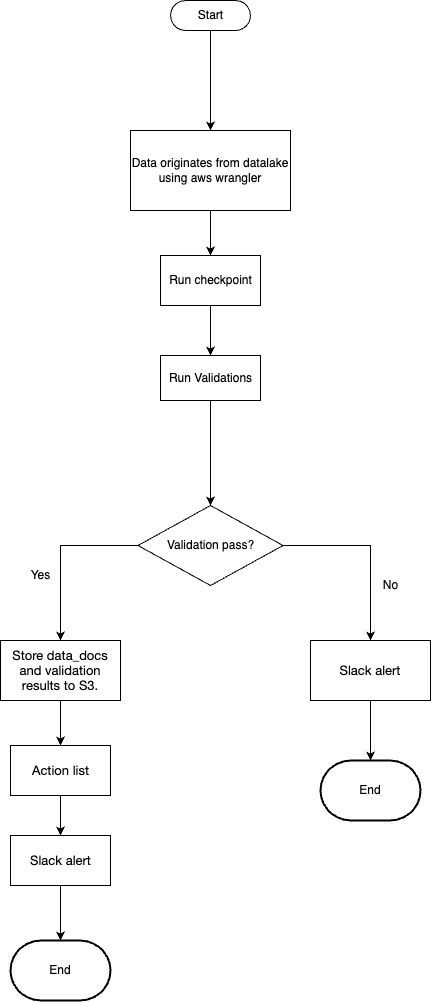
Future development:
We are planning to build custom_expectations for existing data issues which were causing data downtime and bad reports for BI and analyst teams.With custom expectations we can build and modify the expectations suites which can fit to our use case and give us the flexibility to create our own test suites for data quality checks at Halodoc.
Conclusion:
We have shared how we have adopted data quality principles and implemented using Great Expectations over our data lake, can improve the quality of their data and ensure that it is accurate, complete, and consistent.Our data quality framework is constantly evolving as we adopt the best practices from the industry. We are committed to sharing our insights and experiences on how we apply these techniques throughout the data life cycle on our platform. Keep an eye out for our upcoming blog posts on data quality.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


