
Build end-to-end machine learning workflows with Kubernetes and Apache Airflow
Halodoc uses ML at various use-cases from building data products for digital outpatients, insurance, and pharmacy to selecting the right user cohorts for marketing campaigns, accessing the quality of care, serving article recommendations, to adjudicating insurance claims faster. Being able to smoothly build, train and deploy new models is one of our main concerns as Data Scientists.
In the previous blog, we outlined how we built our ML platform using Kubeflow on Amazon EKS to support training models at scale and deploy them for real-time use cases. While it solved our major pain points related to training and deploying models at scale, we were still relying on CRONTAB to schedule batch inference jobs running on EC2 instances.
In this blog, we'll discuss how we leveraged Apache Airflow and Kubernetes allowing us to move beyond CRONTAB and manage our batch inference workloads.
The complex life cycle of a machine learning model
To get a sense of the challenges to bring a model from exploration to production, let’s have a small reminder of the different steps in the life cycle of a machine learning model.
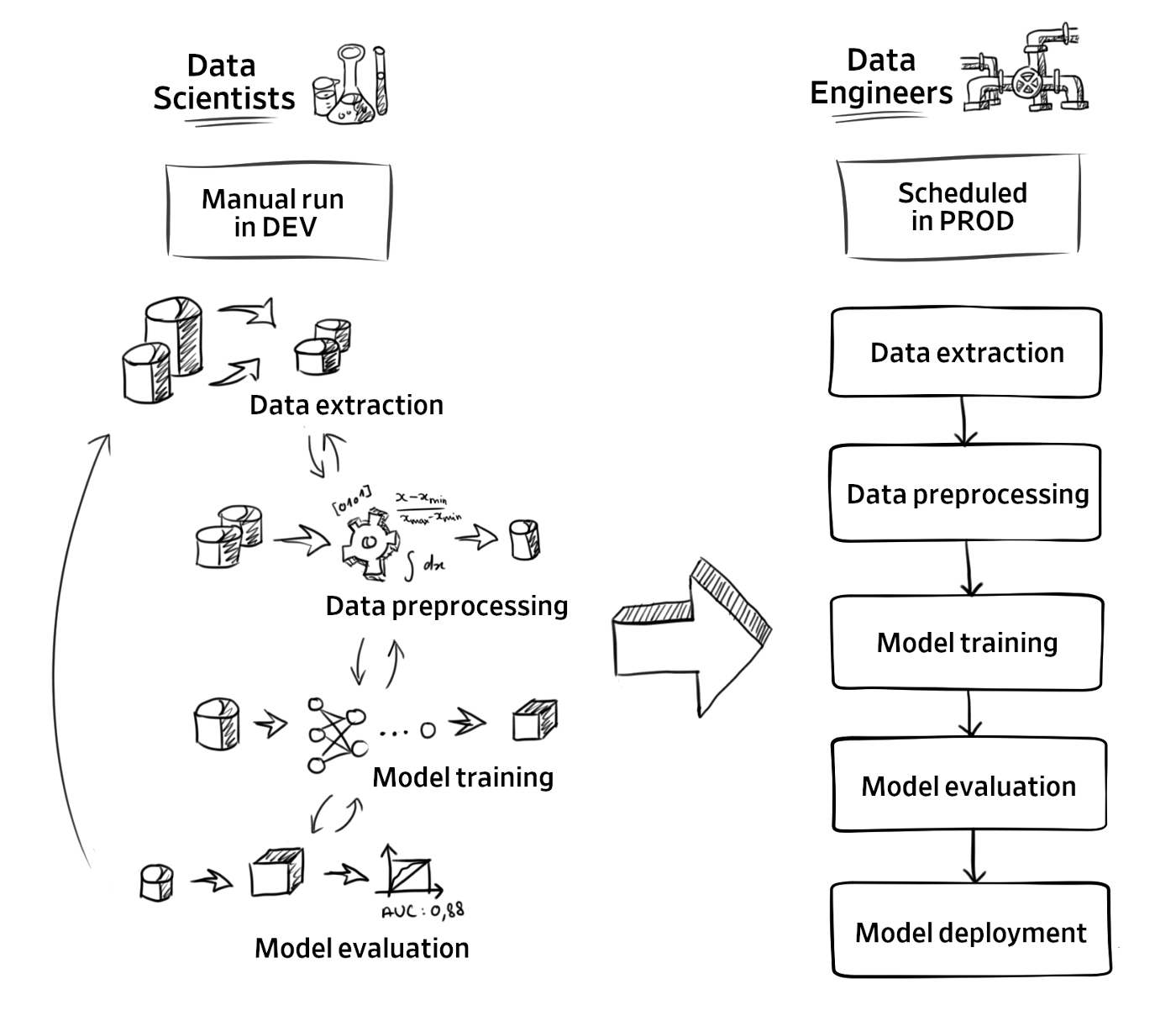
As shown in the above chart, we have different people involved, well as different environments having their own requirements and purposes.
Data scientists are more focused on model performance and will iterate over the process in the development environment, whereas data engineers are more concerned by workflow automation and reliability in production. Depending on the organization, we can either have data scientists or data engineers to schedule the pipelines, but data engineers are the ones who are in charge of providing the framework to do so. While designing this framework, we wanted to ensure that data scientists would have the freedom to use whatever tools they want and computation resources they need.
Overall, the different stages remain almost the same in exploration and production, so we can reuse the code written in exploration when moving to production to avoid any discrepancies and to save time. At Halodoc, we are mainly using AWS to store our data and to build services on top of them. Apache Airflow is our main scheduler and we use MWAA. We will see how both helped us to meet those requirements.
Our first tries in scheduling ML pipelines
For one of our first ML models, SAPE for Assessing the quality of Consultations, we leveraged CRONTAB to schedule the inference jobs on EC2 instances. However, when it came to model training, it was a little bit more tricky as it required specific libraries and machines. Due to a lack of engineering resources and because of short deadlines, the data scientist had to bring this part to production on his own without a well-defined framework. The solution seems good enough, but in fact, it has a serious drawback :
- We are missing the expected features of a good scheduler such as retry on failures, backfill capabilities, and more complex trigger rules and alerts.
- We didn't have the dependencies amongst the jobs well established. if a job is expecting an output from another job. we had to time synchronise it. Apache airflow provides the dependency management in a smooth programmable manner.
Where Airflow and Kubernetes make the difference
The idea was to make use of the EKS node group, each group will provide a type of machine (high memory, high CPU, GPU…) and a set of scopes with auto-scaling enabled. We can then submit our ML jobs in the different pools from airflow using KubernetesPodOperator:
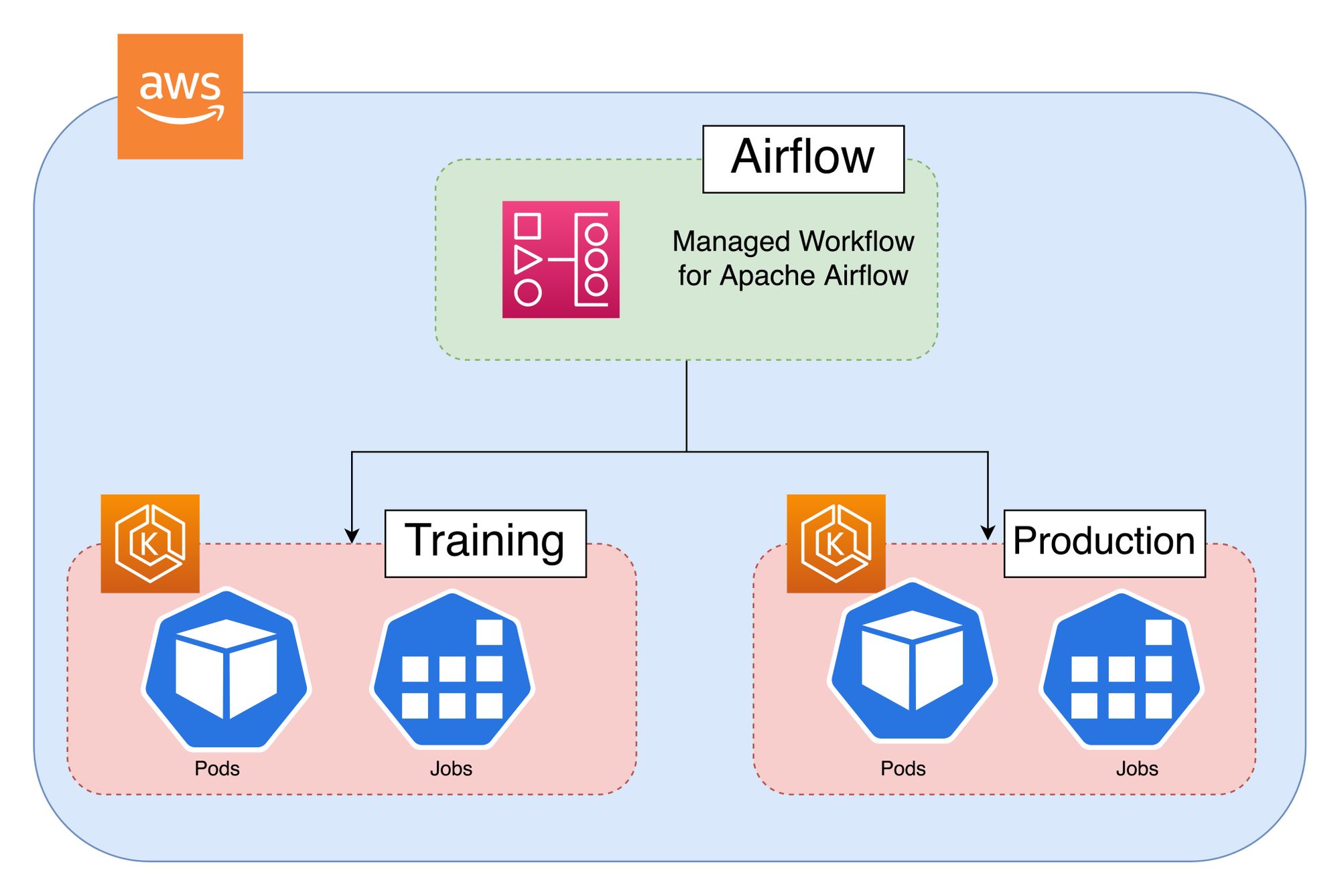
Running our ML tasks in Kubernetes with node pools has several advantages:
- Don’t need to manually manage the creation and destruction of the instances: if there is no pod run on a pool it will downscale automatically to zero and if more resources are needed more nodes will get created.
- Computation resources can be shared. For example, we can have a pod running on a node for a training job. If the node has enough resources, another pod (most likely a lightweight job) can be scheduled on it, avoiding the extra cost (time and money) to create another instance.
- Services can be shared across all the pods in the cluster. For example, we can set up a single Airflow DAG to collect the metrics of our different ML jobs.
Batch Inference pipeline at Halodoc
At the bare minimum, implementing batch inference involves two components. The first component is the compute nodes where these resource intensive workloads will run and the second component is a mechanism to schedule and kickoff the inference logic.
Halodoc's Batch Inference pipeline is hosted on AWS. Our data infrastructure is a combination of AWS managed services and self-hosted services. Comprising of an EKS cluster running Kubernetes and Airflow used for both scheduling inference jobs and also for the data transformations and ingesting the data to Feature store (S3).
To optimise the resource utilization and finding the right balance between cost and performance we are using AWS Graviton powered nodes on our EKS cluster.
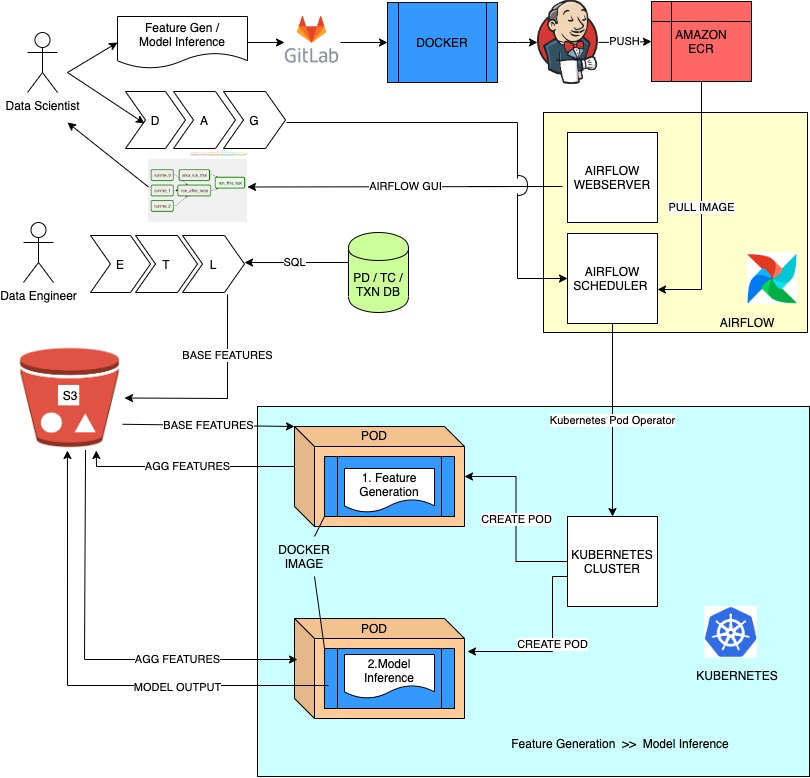
Apache Airflow plays very well with Kubernetes when it comes to schedule jobs on a Kubernetes cluster. KubernetesPodOperator provides a rich set of features that makes things much easier for containerised workloads to be scheduled, monitored in airflow, executed on EKS cluster. Every ML steps such as Feature Generation and Inference are performed using dockered containers stored in AWS Elastic Container Registry. These image urls are captured using Airflow Variables as run time variables.
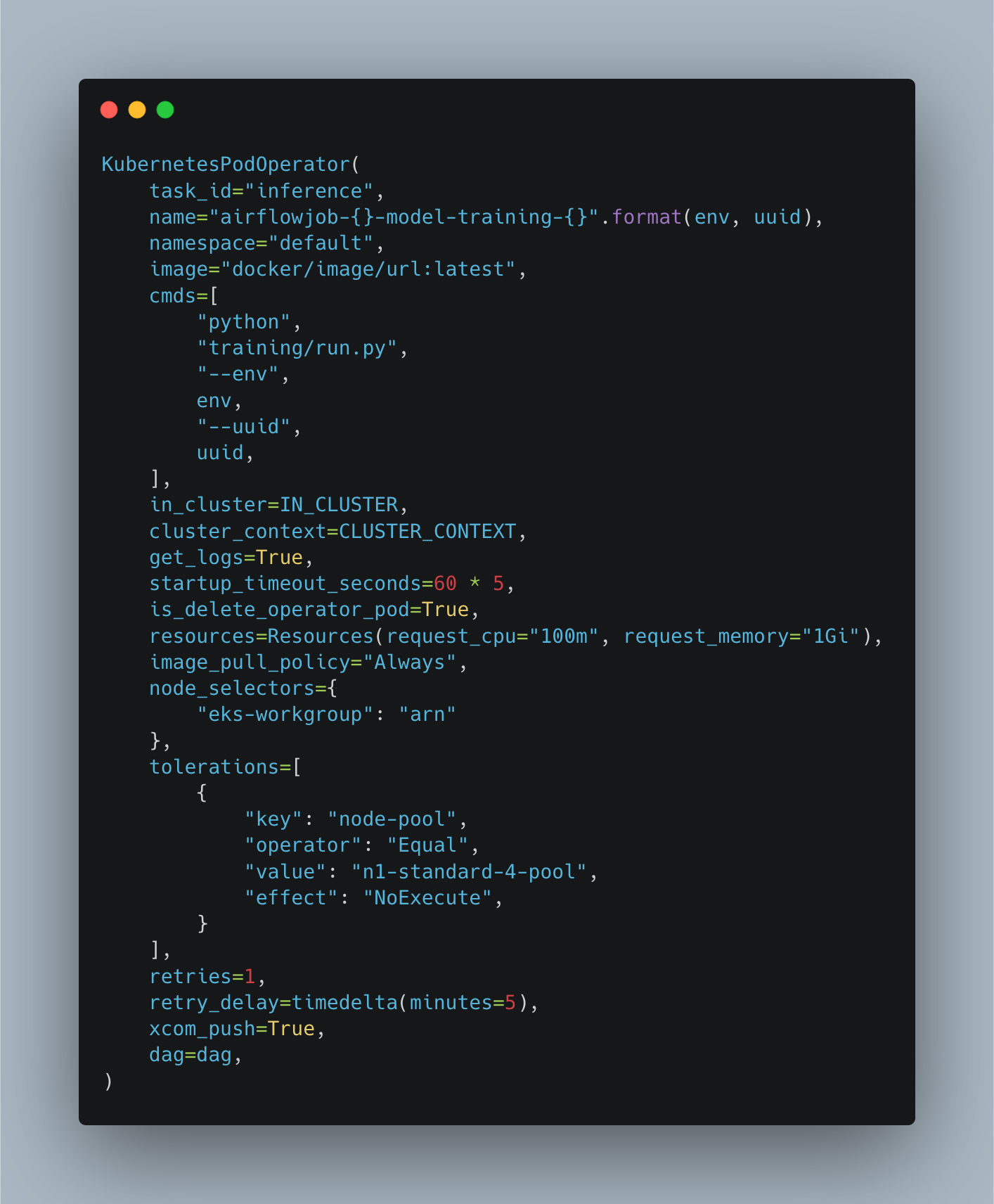
As each of the above parameters (from picture) is important for designing an Airflow DAG to be run on Kubernetes cluster. we use node_selector to customise the configuration of the AWS instance to be used at task level as we had different tasks at different load on the computation/RAM/IO. For instance, the Feature generation task was heavy on computation. Thus we choose heavier instance for Feature Generation. But for model inference (XGboost inference) , it is low on CPU/RAM and we use default low end machine. As the number of models to run per day increases, the computational requirement can be satisfied via auto-scaling option on Kubernetes.
Care should be taken for creating the right set of users with permissions in the kubeconfig file. Setting the right context, namespace amongst the available set of parameters are pivotal.
Final Thoughts
This new Batch Inference Pipeline, enables us to deliver ML models faster into production and ultimately to enhance the user experience with more data-oriented features. Using Airflow to orchestrate our workloads on kubernetes helps us to go away with less reliable CRONTAB and manage multiple ec2 instances running different inference jobs maximizing the resource utilization.
In this blog post, you have seen that building an ML workflow involves quite a bit of preparation but it helps improve the rate of experimentation, engineering productivity, and maintenance of repetitive ML tasks. Airflow provides a convenient way to build ML workflows and integrate with Kubernetes.
You can extend the workflows by customizing the Airflow DAGs with any tasks that better fit your ML workflows, such as feature engineering, creating an ensemble of training models, creating parallel training jobs, and retraining models to adapt to the data distribution changes.
Join Us
We are looking for experienced Data Scientists, NLP Engineers, ML Experts to come and help us in our mission to simplify healthcare. If you are looking to work on challenging data science problems and problems that drive significant impact to enthral you, reach out to us at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.